Also, wie sieht es denn so hinter ns.10be.de aus?
Eigentlich ist 10be nur ein Web-Frontend, welches die Bedienung von der Nightscout-Erstellung erleichtert und im Hintergrund das macht, was Heroku & co auch machen.
Die Einstellungen, welcher der User auf der Seite macht, werden in einer Datenbank gespeichert und zur Nightscout-Instanz weitergeleitet und dort in die Config eingetragen.
Nightscout selbst, händelt dann die ganzen Daten bz, treatments, profile etc und speichert dies in der MongoDB-Datenbank, welche bei 10be für den User beim erstellen vom Server gemacht wurden.
Aus User/Anwender Sicht: Ganz grob so:
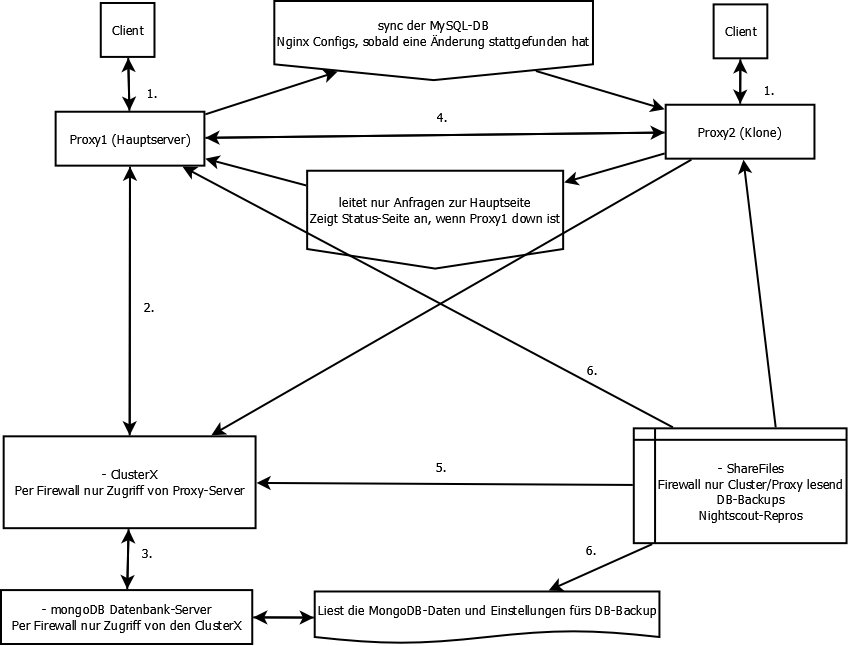
- Also der Client (Browser, App etc), stellt eine Anfrage wie z.B. gib mir die Seite xxxxxxx.ns.10be.de und diese geht beim Proxy1 oder Proxy2 ein (Round Robin).
- Wenn es im nginx eine Config für den Hostnamen oder Port gibt, wird die Anfrage im Hintergrund an den Cluster zu der Nightscout-Instanz weitergeleitet.
- Nightscout selbst, holt sich die Daten aus der MongoDB, die auf dedizierten Server laufen (Ram wäre sonst auf den Clustern zu wenig und ist weniger flexible um eine einzelne Instanz auf einen anderen Cluster zu ziehen).
- Dann wird das Ergebnis an den Client zurück gegeben und die Webseite wird angezeigt.
Und was machen die anderen Sachen da?
- Da werden die Daten auf den zweiten Proxy gesynct, das falls der Hauptserver mal länger ausfällt, man diesen mit etwas Handarbeit als Ersatz nutzten kann.Das es auch ohne eingreifen geht, wäre möglich, aber habe ich noch nicht hinbekommen, da es viel Aufwand ist.
- und 6. Beim share-Server, liegen die Nightscout-Dateien, sowie die DB-Backups und die Autotune-Auswertung.
Die Proxy-Server dürfen lesen auf die DB-Backups zugreifen, ansonsten pusht dieser nur die Daten/Files.Sprich dort werden die neuen Dateien/updates zuerst geladen, dann getestet und dann nach und nach auf den Cluster geladen.
Allgemeine Prüfung der Erreichbarkeit und der Instanzen
Dazu laufen alle paar Minuten Prüfungen ob servername.ns.10be.de:xxx/api/v1/status ein „OK“ zurück gibt und das innerhalb von 3 Sekunden.
Wenn dies in 15 Minuten mehr als 3 Mal fehlgeschlagen ist, wird die Instanz neu deployed.
Dazu laufen auf dem Cluster Daemons, welche prüfen, das die Instanzen laufen und auf dem Port reagieren. Läuft ein Prozess nicht oder antwortet dieser nicht, wird die Instanz neu gestartet.
Prüfung der VPS-Server
Die Server werden alle paar Minuten geprüft, ob diese erreichbar sind und wie der Status vom Server selbst in der api ist.
Wenn ein Server mehrmals nach 30 Sekunden Timeout nicht reagiert, aber gestartet ist, so wird dieser neu gestartet.
Wenn nach einer Stunde immer noch keine Antwort erfolgt, gibt es vom Slack-Bot eine Nachricht und ein reboot wird erneut probiert.
Ebenso wird eine Meldung auf Twitter und hier https://ns.10be.de/de/status.html gepostet.
Dies funktioniert meist gut, aber leider auch nicht immer korrekt, dann muss man immer mal wieder (selten), von Hand eingreifen.
Probleme letzer Woche
Die Hauptprobleme sind mittlerweile der nginx auf Proxy1 und Proxy2.
Die Requesttime liegt meist bei:
req_time=0.002
bis
req_time=0.295
im Normallfall (und aktuell auch wieder).
Bei dem Probleme letzter Woche, gab es aber Werte mit 5 Sekunden und höher, sowie loops, das der Proxy2 erst zum Proxy1 und von dort dann zum Cluster die Verbindung geleitet hat.
Dies kamm zum Teil von dem folgenden Fehler auf dem Proxy1:
could not allocate node in cache keys zone "STATIC"
Und durch die falsche DNS-Auflösung beim proxy2.
Den Fehler von Proxy1 konnte ich leider auch nach vielen Versuchen und Tipps nicht lösen, wodurch der Cache für statische Files, nun komplett deaktiviert ist.
Warum gibt es dann immer noch immer mal wieder Connection Timeouts?
Der Nginx-Dienst muss seit dem die 1.000 Instanzen überschritten wurde, leider mit einem restart neu gestartet werden, da ein reload nicht nur ewig lange dauert, sondern auch danach dieser die neuen Instanzen einfach nicht kennt und daher nicht eingelesen hat.
Beim einem restart werden allerdings die offenen Verbindungen beendet, was zu dem Timeout und ähnlich führen kann. Da dies aber auf dem Proxy1 und 2 mit zwei Minuten Verzögerung passiert, ist immer ein Proxy online.
Man könnte es alles in eine Config-Datei schreiben, dann würde der reload vermutlich gehen, dafür ist aber viel Arbeit zum umbauen der Skripte nötig…….
Allerdings habe ich heute eine andere Änderung gemacht, die es besser machen sollte.
Bitte beachte weiterhin, es ist immer noch ein Gefallen, der hier gemacht wird!
Es gibt keine Garantien oder ähnliches!
Es steckt verdammt viel Arbeit drin und ich versuche mein bestes, aber auch die Freizeit und das Wissen in allen Bereichen ist begrenzt (wächst, aber trotzdem begrenzt).
Von daher, kann es immer wieder zu solchen Probleme kommen und wie beim letzten Fall, wo man denkt, es ist gelöst, tritt dann aber wieder auf und wieder und wieder, kann sich die Lösung hinziehen.
Wer z.B. immer noch Probleme in aaps hat (was bei mir in der DEV nicht auftritt und auch nie aufgetreten ist), kann ich leider nur hier her verweisen:
https://github.com/MilosKozak/AndroidAPS/issues/2481#issuecomment-595903148
[UPDATE 27.05.2020]
Seit den letzten Anpassungen vom März, läuft alles wieder reibungslos.
Das letzte Problem Anfang/Mitte April, das timezone-Paket von npm nun eine Anpassung braucht, die in nightscout noch nicht drin ist, wurde lokal gefixt.
Abgesehen von Hardware-Probleme, die bei einem technischen Defekt auch etwas länger andauern können, gab es keine Verzögerungen, Ausfälle oder ähnliches.